FluentPy Note(1)
python数据模型
如何创建符合python风格的类?
1 | Card = collections.namedtuple('Card', ['rank', 'suit']) |
因__getitem__方法把 [ ] 操作交给self._cards列表,故FrenchDeck自动支持切片。
实现__getitem__方法,这个类就变成可迭代的;实现__len__,则可调用len()
迭代通常是隐式的,譬如一个集合类型没有实现__contains__方法,那么in运算符就会按顺序做一次迭代搜索。于是,in可用在FrenchDeck类上。
以上,通过实现__len()__和__getitem__,FrenchDeck就跟Python自有的序列数据类型一样,可以体现Python语言的核心特性(例如迭代和切片)。
如何使用特殊方法
特殊方法是为被解释器调用的,在执行len(my_object)时,若my_object是自定义对象,那么解释器调用其实现的__len__
如果是内置类型,如list、str、bytearray,CPython会抄近路…,快得多。
很多时候,特殊方法的调用是隐式的,如
for i in x -> iter(x) -> x.__iter__()
通常自己的代码无需直接使用特殊方法,除非有大量的元编程存在。
字符串表现形式
repr()对应__repr__(),str()对应__str__()
!r和!s是对应的格式符
两者的区别在于,__str__是在str()函数被使用,或是在print打印一个对象时候调用,且其返回的字符串更友好,没有引号('')
如果只想实现这两个特殊方法中的一个,__repr__是更好的选择。用为如果没有__str__,解释器会用__repr__作为替代。
自定义布尔值
默认情况下,自定义类的实例总被认为是真,除非这个类对__bool__或者__len__
有自己的实现。bool(x)调用x.__bool__();若未定义__bool__方法,则尝试调用x.__len__()。若返回0,则为False,否则为True。
python中为False
- constants defined to be false:
NoneandFalse. - zero of any numeric type:
0,0.0,0j,Decimal(0),Fraction(0, 1) - empty sequences and collections:
'',(),[],{},set(),range(0)
python特殊方法
| 类别 | 方法名 |
|---|---|
| 字符串/字节序列表示形式 | __repr__ __str__ __format__ __bytes__ |
| 数值转换 | __abs__ __bool__ __complex__ __int__ __float__ __hash__ __index__ |
| 集合模拟 | __len__ __getitem__ __setitem__ __delitem__ __contains__ |
| 迭代模拟 | __iter__ __reversed__ __next__ |
| 可调用模拟 | __call__ |
| 实例创建和销毁 | __new__ __init__ __del__ |
| 属性管理 | __getattr__ __getattribute__ __setattr__ __delattr__ __dir__ |
| 属性描述符 | __get__ __set__ __delete__ |
小结:通过实现特殊方法,自定义数据类型可以表现得跟内置类型一样,从而让我们写出更具表达力的代码——或者说,更具 Python 风格的代码。
数据结构
python序列类型
- 容器序列:list、tuple和collections.deque 这些序列存放不同类型的数据。
- 扁平序列:str、bytes、bytearray、memoryview和array.array 这些只能容纳一种类型
容器序列存放的是任意类型对象的引用,而扁平序列存放的是值。即,扁平序列其实是一段连续的内存空间。由此可见,扁平序列更加紧凑,但只能存诸如字符、字节和数值这些基础类型。
序列还能按是否被修改分类:
- 可变序列 list、bytearray、array.array、collections.deque和memoryview
- 不可变序列 tuple、str和bytes
列表推导
内置函数 ord() :返回字符的Unicode码,如ord(‘a’)返回97; 与 chr() 效果相反。
列表推导同filter和map比较
1 | symbols = '$¢£¥€¤' |
生成器表达式
虽然也能用列表推导来初始化元组、数组和其他序列类型,但生成器是更好的选择。
因为生成器表达式遵守迭代器协议,可逐个产出元素,而不是建立一个完整的列表,节约内存。
1 | tuple(ord(symbol) for symbol in symbols) |
元组
可用作不可变的列表,还可以用于没有字段名的记录。
若将元组理解为数据记录:元组中的每个元素都存放了记录中一个字段的数据,外加这个字段的位置。
元组拆包
元组拆包可应用到任何可迭代的对象上(可迭代元素拆包)。
平行赋值
latitude, longitude = (33.9425, -118.408056)还可以用
*运算符把可迭代对象拆开作为函数的参数quotient, remainder = divmod(*t)。拆包中,_ 为占位符。
用来处理剩下的元素 ` a, b, rest = range(5)`
嵌套元组拆包
1
for name, cc, pop, (latitude, longitude) in metro_areas:
具名元组
1 | Card = collections.namedtuple('Card', ['rank', 'suit']) |
namedtuple构建的类的实例所消耗的内存跟元组一样,因字段名都被存在对应的类里。
这个实例跟普通的对象实例比起来也要小一些,因Python不会用__dict__来存放这些实例的属性。
具名元组的专有属性:
_fields属性是一个包含这个类所有字段的元组_make()通过接受一个可迭代对象来生成这个类的一个实例_asdict()把具名元组以collections.OrderedDict形式返回,友好呈现数据
切片
s[a:b:c]形式对s在a和b之间以c为间隔取值。c也可以为负,意味反向取值。
1 | s = 'bicycle' |
可以把切片放在赋值语句左边,或把它作为del操作的对象。
对序列使用+和*
1 | l = [1, 2, 3] |
注意在l*n语句中,当序列 l里的元素是对其他可变对象的引用时:
如 my_list= [[]]*3,此时得到的列表里包含的其实是三个引用,而这三个引用指向的是用一个列表。
序列的增量赋值
+=背后的特殊方法是__iadd__(“就地加法”)。但如果一个类没有实现这个方法的话,Python会退一步调用__add__。
1 | a += b |
如果 a 实现了__iadd__ 方法,就会调用这个方法。同时对可变序列(例如 list、bytearray 和 array.array)来说,a 会就地改动,就像调用了 a.extend(b) 一样。但是如果 a 没有实现__iadd__ 的话,a+= b 这个表达式的效果就变得跟 a = a + b 一样了:首先计算 a +b,得到一个新的对象,然后赋值给 a。
list.sort()和内置的sorted()
参数:reversed 、key
可用bisect管理已排序的序列
当列表不是首选时
- 存放1000万个浮点数,数组(array)的效率要高得多,因数组背后存放的不是float对象,而是数字的机器翻译,也就是字节表述。
- 如果需要频繁对序列做先进先出的操作,deque(双端队列)的速度更快。
- 若检查一个元素是否出现的操作频率很高,用set更合适。
数组
如果需要一个只包含数字的列表,那么 array.array 比 list 更高效。数组支持所有跟可变序列有关的操作,包括 .pop 、.insert 和 .extend。另外,数组还提供从文件读取和存入文件的更快的方法,如 .frombytes 和 .tofile。
创建数组需要指定类型码,如
- b 类型码代表有符号的字符(signed char)
- d 代表双精度实数
- h 代表短整型有符号整数
1 | floats = array('d', (random() for i in range(10 ** 7))) |
数组排序,需新建一个数组a = array.array(a.typecode, sorted(a))
memoryview是内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片。
双向队列和其他形式队列
列表利用 .append 和 .pop(0) 合起来,就能模拟队列“先进先出”特点,但是删除列表的第一个元素(在第一个元素前插入元素)之类的操作很耗时,因这些操作牵扯移动列表里所有元素。
collections.deque(双向队列)是一个线程安全、可以快速从两端添加或删除元素的数据类型。
1 | dq = deque(range(10), maxlen=10) |
双向队列也付出了一些代价,从队列中间删除元素的操作会慢一些,因为它只对在头尾的操作进行了优化。
字典和集合
泛映射类型
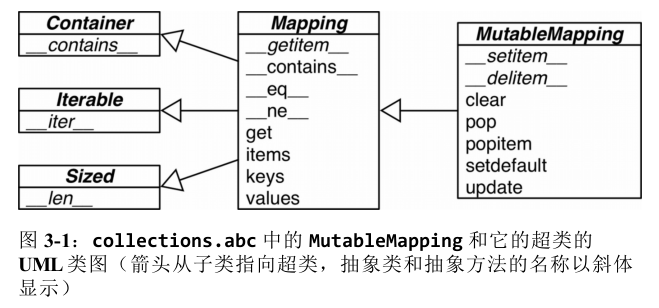
以上是形式化的文档,定义了最基本的接口,还可以用来跟 isinstance 做类型判断。非抽象映射类型一般直接对 dict 或是 collections.User.Dict 进行扩展。
标准库中所有的映射类型都是利用dict来实现的,因此有共同的限制,即只有可散列的数据类型才能用作这些映射里的键(值不需要可散列)。
什么是可散列的?
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的。而且这个对象需要实现__hash__(),还要有__qe__()。如果两个可散列的对象是相等的,散列值一定相等。
原子不可变数据类型(str、bytes 和数值类型)都是可散列类型,frozenset 也是可散列的,因为根据其定义,frozenset 里只能容纳可散列类型。元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
字典构造
1 | a = dict(one=1, two=2, three=3) |
字典推导
1 | country_code = {country: code for code, country in DIAL_CODES} |
用setdefault处理找不到的键
可以用 d.get(k, default) 来代替 d[k],给找不到的键一个默认的返回值(这比处理 KeyError 要方便不少)
1 | my_dict.setdefault(key, []).append(new_value) |
等价于
1 | if key not in my_dict: |
映射的弹性键查询
有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。
一个是通过 defaultdict 这个类型而不是普通的 dict,另一个是给自己定义一个 dict 的子类,然后在子类中实现 __missing__ 方法。
对于defaultdict:
如 dd = defaultdict(list),这里将 list 指定为 default_factory,它是defaultdict用来生成默认值的实例属性,需要存放可调用对象。
这里,若dd['new_key']中键 ‘new_key’ 不存在的话,按以下处理:
- 调用 list() 来建立一个新列表。
- 把这个新列表作为值,’new-key’ 作为它的键,放到 dd 中。
- 返回这个列表的引用。
defaultdict 里的 default_factory 只会在__getitem__里被调用,也就是dd[k]会调用default_factory,而dd.get(k)则会返回None。
所有这一切背后的功臣其实是特殊方法 __missing__。它会在defaultdict 遇到找不到的键的时候调用 default_factory,而实际上这个特性是所有映射类型都可以选择去支持的。
特殊方法__missing__
如果有一个类继承了 dict,然后这个继承类提供了__missing__方法,那么在 __getitem__ 碰到找不到的键的时候,Python 就会自动调用它,而不是抛出一个 KeyError 异常。
__missing__ 方法只会被 __getitem__ 调用(比如在表达式 d[k] 中)
字典的变种
collections.OrderedDict
这个类型添加键时会保持顺序,因此键的迭代次序总是一致的。
collections.ChainMap
该类型可容纳数个不同的映射对象,然后查找时,会当作一个整体查找,直到键被找到为止。如Python变量查找规则:
1 | import builtins |
collections.Counter
这个类会给键设置一个整数计数器。更新键时会增加这个计数器,可用来计数。
不可变映射类型
types 模块中引入了一个封装类名叫MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
集合论
集合中的元素必须是可散列的,set类型本身是不可散列的,但是frozenset可以。因此可以创建一个包含不同frozenset的set。
集合中缀表达式: a | b : 并集、 a & b : 交集、a - b : 差集
如:needles 的元素在 haystack 里出现的次数,两个变量都是 set 类型
1 | found = len(needles & haystack) |
以上代码可以用在任何可迭代对象上:
1 | found = len(set(needles) & set(haystack)) |
集合字面量
集合字面量 : {…},空集:set()
集合推导 {func(i) for i in iterable}
dict与散列表
由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。
用
元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
set与散列表
set 和 frozenset 的实现也依赖散列表,但在它们的散列表里存放的只有元素的引用(就像在字典里只存放键而没有相应的值)。在 set 加入到 Python 之前,我们都是把字典加上无意义的值当作集合来用的。
一等函数
高阶函数
接受函数为参数,或者把函数作为结果返回的函数是高阶函数。
可调用对象
- 用户定义的函数:使用 def 语句或 lambda 表达式创建。
- 内置函数:使用 C 语言(CPython)实现的函数,如 len 或 time.strftime。
- 内置方法:使用 C 语言实现的方法,如 dict.get。
- 方法:在类的定义体中定义的函数。
- 类:调用类时会运行类的
__new__方法创建一个实例,然后运行__init__方法,初始化实例,最后把实例返回给调用方。因为 Python没有 new 运算符,所以调用类相当于调用函数。 - 类的实例:如果类定义了
__call__方法,那么它的实例可以作为函数调用。 - 生成器函数:使用yield关键字的函数或方法。调用生成器函数返回的是生成器对象。
callable()判断对象是否可以调用。
从定位参数到仅限关键字参数
1 | def tag(name, *content, cls=None, **attrs): |
以上 cls参数 只能通过关键字指定,它一定不会捕获未命名的定位参数。
定义函数时若想指定关键字参数,要把它们放到有 的参数后面。如果不想支持数量不定的定位参数,但想支持仅限关键字参数,在签名中放一个 ,如下:
1 | def f(a,*,b): |
注意,仅限关键字参数不一定要有默认值,可以像上例中 b 那样,强制必须传入实参。
内省:获取关于参数的信息
与内省有关的函数对象
__defaults__属性,它的值是一个元组,保存着定位参数和关键字参数的默认值。__kwdefaults__属性,保存仅限关键字参数默认值。__code__属性,保存参数的名称,它的值是一个code对象的引用,自身也有很多属性。
相关模块:inspect
支持函数式编程的包
operator模块为多个算术运算符提供了对应的函数,从而避免编写平凡的匿名函数。
1 | from functools import reduce |
operator模块中的itemgetter、attrgetter能从序列中取出元素或读取对象属性。
1 | for city in sorted(metro_data, key=itemgetter(1)): |
itemgetter使用[]运算符,因此它不仅支持序列,还支持映射和任何实现__getitem__方法的类。
attrgetter 与 itemgetter 作用类似,它创建的函数根据名称提取对象的属性。如果把多个属性名传给 attrgetter,它也会返回提取的值构成的元组。此外,如果参数名中包含 .(点号),attrgetter 会深入嵌套对象,获取指定的属性。
1 | from operator import attrgetter |
functools.partial冻结参数
1 | from functools import partial |
使用函数实现设计模式
策略模式
1 | class Order: # 上下文 |
函数装饰器和闭包
装饰器是可调用对象,其参数是另一个函数(被装饰的函数)。装饰器可能会处理被装饰的函数,然后把它返回,或者将其替换成另一个函数或可调用的对象。
1 |
|
严格来说,装饰器只是语法糖。
Python在何时执行装饰器?
函数装饰器在导入模块时立即执行,而被装饰的函数只在明确调用时运行。这突出了导入时和运行时的区别。
使用装饰器改进策略模式
1 | promos = [] |
变量作用域规则
1 | b = 6 |
Python不要求声明变量,但是假定在函数定义体中的变量是局部变量,参数也是。
闭包
闭包是指延伸了作用域的函数,其中包含函数定义体中引用、但是不在定义体中定义的非全局变量。

综上,闭包是一种函数,它会保留定义函数时存在的自由变量的绑定。这样调用函数时,虽然定义作用域不可用了,但仍能使用那些绑定。
nonlocal声明
1 | def make_averager(): |
实现一个简单的装饰器
装饰器的典型行为:把被装饰的函数替换成新函数,二者接受相同的参数,而且(通常)返回被装饰函数本该返回的值,同时做些额外的操作。
1 | def clock(func): |
以上实现的装饰器有缺点:遮盖了被装饰函数的__name__和__doc__属性。
可使用functools.wraps 装饰器把相关的属性从 func 复制到 clocked 中。
1 | def clock(func): |
Python 内置了三个用于装饰方法的函数:property、classmethod 和staticmethod。
另一个常见的装饰器是 functools.wraps,它的作用是协助构建行为
良好的装饰器。标准库中最值得关注的两个装饰器是 lru_cache 和全新的 singledispatch。
functools.lru_cache做备忘
1 |
|
functools.singledispatch 装饰器
它可以把整体方案拆分成多个模块,甚至可以为你无法修改的类提供专门的函数。使用@singledispatch装饰的普通函数会变成泛函数(generic function):根据第一个参数的类型,以不同方式执行相同操作的一组函数。
1 | # @singledispatch标记处理object类型的基函数 |
以上各个专门函数使用@base_function.register(type)装饰。专门函数的名称无关紧要;使用 _ 简单明了。
只要可能,注册的专门函数应该处理抽象基类(如 numbers.Integral和 abc.MutableSequence),不要处理具体实现(如 int 和list)。这样,代码支持的兼容类型更广泛。
参数化装饰器
怎么让装饰器接受其他参数?
创建一个装饰器工厂函数,返回装饰器。
1 | registry = set() |
对象引用、可变性和垃圾回收
== 运算符比较两个对象的值(对象中保存的数据),而 is 比较对象的标识。
元组的相对不可变性
元组与多数Python容器(列表、字典、集)一样,保存的是对象的引用。元组的不可变性其实是指tuple数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
元组的相对不变性也是,有些元组不可散列的原因。
默认做浅复制
复制列表(或多数内置的可变集合)最简单的方式是使用内置类型的构造方法。
1 | l1 = [3, [55, 44], (7, 8, 9)] |
以上看出,二者指代不同的对象。对列表和其他可变序列来说,还能使用简洁的l2=l1[:]语句来创建副本。
然而,构造方法或[:]做的是浅复制(即复制了最外层的容器,副本中的元素是源容器中元素的引用)。如果所有的元素都是不可变的,那么这样没问题。但是,如果有可变元素,可能就会导致意想不到的问题。
1 | import copy |
浅复制,不同引用,同一个对象;深复制,不同引用,不同对象。
函数的参数作为引用时
Python 唯一支持的参数传递模式是共享传参。共享传参指函数的各个形式参数获得实参中各个引用的副本。也就是说,函数内部的形参是实参的别名。
Java 的引用类型是这样,基本类型按值传参(函数得到参数的副本)。
函数可能会修改接收到的任何可变对象
1 | def f(a, b): |
防御可变参数
不要使用可变类型作为参数的默认值。
del和垃圾回收
del 语句删除名称,而不是对象。del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。 重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
符合Python风格的对象
因Python数据模型,自定义类型行为可以像内置类型那样自然。实现如此自然的行为,靠的不是继承,而是鸭子类型(会叫即鸭子):只需按照预定行为实现对象所需的方法(一般特殊方法)即可。
classmethod与staticmethod
classmethod定义操作类,而不是操作实例的方法。classmethod中第一个参数始终是类本身。classmethod最常用的用途是定义备选构造方法。staticmethod就是普通函数,只是碰巧在类的定义中。
格式化显示
'{0.mass:5.3e}' 这样的格式字符串其实包含两部分,冒号左边的 ‘0.mass’ 在代换字段句法中是字段名,冒号后面的 ‘5.3e’ 是格式说明符
str.format() 格式说明符使用的表示法是格式规范化微语言(formatspec)。
New in Python3.6
f-string 真正的运行时计算;双引号
!r 调用 repr()、!s调用 str()、!a调用ascii()
Python的私有属性和“受保护的”属性
为避免子类意外覆盖“私有”属性,以形如__mode的形式(两个前导下划线)命名实例属性,Python会把属性名存入实例的__dict__属性中,而且会在前面加一个下划线和类名,因此有_Class__mode和_Subclass__mode。
有些Python程序员约定使用一个下划线前缀编写“受保护”的属性(如 self._x)。
默认情况下,各个实例在名为__dict__的特殊属性中存储实例属性。
__slots__类属性,让解释器在元组中储存实例属性,而不是用字典。这样节省大量内存。在类中定义__slots__ 属性的目的是告诉解释器:“这个类中的所有实例属性都在这儿了!”
仅当权衡当下的需求并仔细搜集资料后证明确实有必要时,才应该使用__slots__ 属性。
覆盖类属性
Python中:类属性可用于为实例属性提供默认值。
为不存在的实例属性赋值,会创建新的实例属性。为实例属性赋值后,同名的类属性不受影响。然而自此之后,self.objattr读取的是实例属性objattr,也就把类属性覆盖了。
在 Python中,我们可以先使用公开属性,然后等需要时再变成特性。
序列的修改、散列、切片
序列类型的构造方法应该接受可迭代的对象为参数,因为所有内置的序列类型就是这样做的。
切片原理
Python如何把seq[1:3]句法变成传给seq.__getitem__(...)的参数。
1 | class MySeq: |
indices:假设有个长度为 5 的序列,例如 ‘ABCDE’:
1 | slice(None, 10, 2).indices(5) # ➊ |
❶ ‘ABCDE’[:10:2] 等同于 ‘ABCDE’[0:5:2]
❷ ‘ABCDE’[-3:] 等同于 ‘ABCDE’[2:5:1]
当没有底层序列类型作为依靠,那么使用此方法能节省大量时间。
属性查找失败后,解释器会调用__getattr__方法。简单来说,对my_obj.x 表达式,Python 会检查 my_obj 实例有没有名为 x 的属性;如果没有,到类(my_obj.__class__)中查找;如果还没有,顺着继承树继续查找。 如果依旧找不到,调用 my_obj 所属类中定义的__getattr__ 方法,传入 self 和属性名称的字符串形式(如 ‘x’)。
zip函数
zip函数用于并行迭代两个或多个可迭代对象。当一个可迭代的对象耗尽后,它不发出警告就停止。itertools.zip_longest函数的行为有所不同:使用可选的fillvalue填充缺失的值,直到最长的可迭代对象耗尽。
为了避免在for循环中手动处理索引变量,还经常使用内置的enumerate生成器函数。
抽象基类
抽象基类常见用途:实现接口时作为超类使用。抽象基类如何检查具体子类是否符合接口定义?如何使用注册机制声明一个类实现了某个接口,而不进行子类化操作。最后说明如何让抽象基类自动“识别”任何符合接口的类——不进行子类化或注册。
Python 是动态语言,因此我们可以在运行时修正一些问题。
object does not support item assignment 问题:可变的序列还必须提供 __setitem__方法。
标准库中的抽象基类
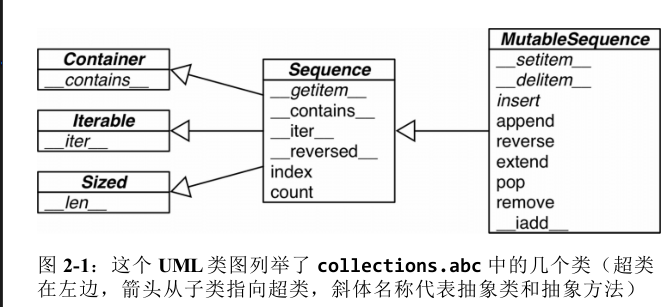
collections.abc中的抽象基类最常用。
自定义抽象基类
抽象方法使用@abc.abstractmethod标记,而且定义体中通常只有文档字符串。”是否实现抽象方法”基类检测子类是否符合接口的依据。
声明抽象基类最简单的方法是继承abc.ABC或其他抽象基类。
声明抽象类方法
1 | class MyABC(abc.ABC): |
与其他描述符一起使用时,abstractmethod()应放在最里层。
虚拟子类
Python新编程风格:使用抽象基类明确声明接口,而且类可以子类化抽象基类或抽象基类注册(无需在继承关系中确立静态的强链接),宣称它实现了某个接口。
继承的优缺点
不要子类化内置类型,自定义类应该继承collections模块中的类,例如UserDict、UserList和UserString,它们易于扩展。
运算符重载
一元运算符
- (__neg__) 、+ (__pos__)、 ~(__invert__)
支持一元运算符很简单,只需实现相应的特殊方法。这些特殊方法只有一个参数,self。运算符一个基本规则:始终返回一个新对象。也就是说,不能修改self,要创建并返回合适类型的新实例。